Email article
Email article

In an effort to improve transparency, Google began publishing reports on the DMCA takedown requests it receives. According to Google, removal requests are now up from 250,000 weekly in May, to 2.5 million requests weekly today. Unfortunately for copyright holders and their never-ending battle against piracy, not all these requests are legitimate ones.
According to a report on TorrentFreak, while some of the content is being flagged as false due to them no longer being on the original site, the automated systems that are being used by copyright holders include perfectly legitimate content as well. One example from Google can be quite humorous when you think about it as it is very obvious that it is a false request:
A major U.S. motion picture studio requested removal of the IMDb page for a movie released by the studio, as well as the official trailer posted on a major authorized online media service.
Google of course does not remove any links that they find to be non-infringing, and along with the false takedown requests like the one quoted above, they are included in the transparency report and marked as “no action taken.”
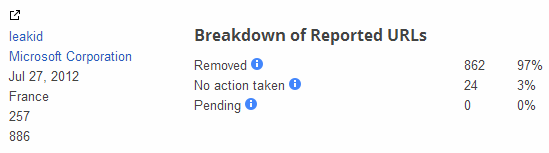
Among the more notable false requests, we have Microsoft requesting Google to censor AMC Theatres, BBC, Buzzfeed, CNN, HuffPo, TechCrunch, RealClearPolitics, Rotten Tomatoes, ScienceDirect, Washington Post, Wikipedia and even the U.S. Government. All of which you’d be hard-pressed to ever find hosting any sort of copyright-infringing content.
Google is certainly on the right track with what its been doing lately, managing to appease companies by taking in their requests while still providing all the transparency the public could ask for in their reports. Now if only the copyright holders could help them out and get their automated systems in check. All these thousands of false requests can only be one other thing besides ridiculous at times — they’re a waste of time.
[via TorrentFreak, image via methodshop]